Building The Data Mart
Marc Demarest
marc@noumenal.com
November 1993

|
Publication History A version of this paper appeared in DBMS Magazine in July 1994 (v7 n8 p44). This appearance was the first systematic treatment of the concept of data marting and its relationship to data warehousing. Although the concept of data marting, and the architectural model of combining a single warehouse and multiple marts into an enterprise-wide decision support environment, are now taken for granted by most DSS architects and system builders, at the time the article was published, the concept of marting was extremely controversial. See for example the somewhat scathing comments on marting by Ralph Kimball, in an interview in the same issue of DBMS in which this article first appeared. |
Data warehousing, in practice, focuses on a single large server or mainframe that provides a consolidation point for enterprise data from diverse production systems. It protects production data sources and gathers data into a single unified data model, but does not necessarily focus on providing end-user access to that data (data warehouse designers often treat end-user access as an afterthought).
Data marting, conversely, deals almost exclusively with servicing a distinct community of knowledge workers. As a model, data marting ignores the practical difficulties of protecting production systems from the impact of extraction, focusing instead on the knowledge worker's need for information from diverse production systems consolidated into a model that reflects the knowledge worker's understanding of the business.
By creating a multitiered decision-support model that blends warehousing and marting, organizations can achieve the long-term benefits promised by data warehousing without compromising the immediate business requirements of data-hungry knowledge workers. This hybrid approach can lower the operating costs associated with legacy systems used for decision support, and, when feasible, enable the removal of those legacy systems from the IS environment. The multitiered architecture can also deliver new value to DSS end users through the judicious application of client/server and GUI technologies.
Finally, the hybrid model can enhance competitive advantage in the marketplace through a Unified Data Architecture (UDA). The UDA lets business decision makers monitor their pieces of the business at the appropriate level of detail, model the cross-organizational business processes that their work affects, and predict the future impact of business decisions on other areas of the enterprise.
Data Warehousing Overview
In the late 1970s, it became apparent that mainframe-based production systems could not support enterprise-wide decision support. These systems fragmented fundamental business "objects," such as customers and markets, into transaction-level detail data spread across many production databases, and they could not sustain the performance levels required by mission-critical applications while simultaneously servicing knowledge workers' complex queries. In addition, the production systems captured only a small part of the data required for business decision making, and they could not support the semistructured, collaborative nature of decision making in the modern knowledge-based firm.
In response to these shortcomings, decision-support theorists abandoned the idea that decision making was strictly an "executive" function to be supported by host-based executive information systems (EISs). Instead, they began to discuss an alternative strategy for large-scale decision support known as data warehousing, a term coined by W.H. Inmon and popularized by IBM as "information warehousing."

Figure 1 -- Paradigm Shift in DSS Models
The basic data warehousing architecture interposes between end-user desktops and production data sources a warehouse that we usually think of as a single, large system maintaining an approximation of an enterprise data model (EDM). Batch processes populate the warehouse through off-peak extraction from production data sources, and, in theory, the warehouse responds to end-user requests for information passed to it through conventional client/server middleware.

Figure 2 -- Basic Data Warehousing Model
Data warehousing as an architectural model has four fundamental goals:
1) to protect production systems from query drain by moving query processing onto a separate system dedicated to that task, and extracting all the relevant information from each production data source at predictable times when off-peak usage patterns prevail;
2) to provide a traditional, highly manageable data center environment for DSS using tools and practices comparable to those used in data center OLTP;
3) to build a UDA or EDM in the warehouse, so that data from disparate production systems can be related to other data from different production systems in a logical, unified fashion. This would align processes across the organization using a common vocabulary (for example, "customer" would mean the same thing throughout the enterprise), which would simplify the modeling of complex future business behavior and performance based on historical data; and
4) to separate data management and query processing issues from end-user access issues so that they can be treated as distinct problems.
Ultimately, the data warehouse can serve as the basis for complex, forward-looking business modeling activities in which strategic planners and business managers use neural networks and other artificial intelligence technologies to surf historical data and predict future business trends.
The data warehouse model has merit, but falls short as a comprehensive decision-support solution. Let's review its four goals. The first goal of data warehousing (protecting production systems) is a worthy one, and necessary for maintaining adequate levels of performance and end-user response times. The second goal (improving data manageability) also has merit, because DSS data represents a strategic asset of the firm. DSS data is not just a copy of data held elsewhere in the environment; rather, it is a unique, enriched data set.
The third goal (creating an EDM) is an honorable but expensive proposition, in terms of both technology and time, and is flawed for nontechnical reasons. Autonomous business units with their own IT functions may refuse to deliver data or metadata to data architects. Legal requirements for different countries or regions may make it impossible to define a standard set of attributes for an entity. Also, affordable tools may not exist to manage data that resides in various proprietary and open system data stores. Finally, any EDM will require constant revision (if not complete renovation) on an annual basis because of rapidly changing business conditions. The cost of this constant management activity may be too high for a firm to bear.
The fourth goal (separating functions) also represents a shortcoming of data warehousing. By focusing on data modeling and management and not on direct end-user data access, data warehousing in practice requires expensive paper-based reporting process that SQL and 4GL programmers have to service. Also, data warehousing has historically encouraged the creation of nonportable reporting applications based on proprietary technologies such as 3270 terminals and CICS that today do not represent the leading edge of technology. More important, these technologies do not reflect what business teams use today, such as personal computers, GUIs, and personal and LAN-based workgroup productivity tools.
Data warehouses did not anticipate the dynamism of late twentieth-century markets or the structural realignments required in companies to service those markets. They relied on a static notion of the market and the company, and fixed that notion in a data model. And because data warehouses demanded an impractical degree of completeness, they failed to deliver working data models in a reasonable amount of time.
Ultimately, data warehousing ignored the personal computer and the knowledge worker. As organizations gave more user communities access to the data warehouse, significant warehouse maintenance problems came to light. First, the number of tables increased dramatically (in what I call schema explosion) as each constituent community added new views, summary tables, aggregations, and precalculations, to the transaction-level detail. As a result of this increase in tables, the legibility -- the knowledge workers' ability to navigate the warehouse efficiently -- suffered. In my experience, when the warehouse contains more than approximately 20 tables, the average knowledge worker's ability to navigate the warehouse becomes impaired.
Data Marting Overview
The failure of data warehousing to address the knowledge worker's culture and the practical technical difficulties associated with EDM development and warehouse maintenance prompted Forrester Research in 1991 to declare that data warehousing was dead. It had been replaced by what Forrester called data marting. Data marts are user community-specific data stores that focus on DSS end-user requirements. In effect, data marting attempts to solve the enterprise DSS problem by presenting only the data that an end-user constituency requires in a form close to the constituency's business model.

Figure 3 -- Basic Data Marting Model
Data marting has advantages over data warehousing. For example, the data mart focuses on data legibility: The business team sees only the data it needs, in a form that matches its collective understanding of the business. The data mart makes full use of today's LAN-based client/server technologies, integrates with the knowledge workers' toolset, and rides the price-performance curve of those technologies. A data mart provides a homogeneous population of knowledge workers with similar business models, business vocabularies, and responsibilities.
The data marting model supports individual knowledge worker communities quite well. However, it also has disadvantages when seized by LAN independent software vendors (ISVs) as the basis for bidding for corporate IS attention, or by knowledge workers as a pretext for circumventing corporate or divisional IS data architecture efforts by building unauthorized data marts in departments and work-groups outside IS control.
Data marting also overestimates the capability and performance of LAN-based data-management tools. For example, flat-file DBMSs and small-scale RDBMSs do not have the processing power or the facilities to support a high-performance query environment, nor can you connect them to production data sources in a way that allows efficient and timely large-scale extracts. Data marting also neglects -- as do most LAN-based models -- the technical limitations of mainframe-based production systems in providing extract processing time and power. It also neglects the secondary systems and network management morass that is created when many data marts request substantial data extractions from multiple production systems.
Data marting addresses the decision-support needs of only small companies with few knowledge workers, single markets, and simple product lines. On its own, data marting cannot meet the needs of international enterprises with many distinct knowledge edge worker communities, many products and markets, and constant reorganization in response to market conditions.
Perhaps most ironically, data marting neglects the real organizational boundaries drawn in large companies between data management and data movement. While divisional IS organizations can build data marts for their knowledge workers, corporate IS data architects and DBAs may not be willing to populate those marts with corporate data.
Blending the Models
The basis of good enterprise DSS architectures is the concept of information-on-demand: giving knowledge workers the data they need, when they need it, where they need it. For the knowledge worker, data is a raw material that IS organizations are expected to supply as needed. The concept of an "information warehouse" is misleading and inappropriate because information is created dynamically by teams of knowledge workers. It is not stored in a musty repository, among the tuples, waiting to be discovered.
Knowledge workers are the customers of DSS architectures and implementations; data is the raw material they require. Systems architects must deliver the raw material and, to some extent, support the work processes through which knowledge workers transform that raw material into useful information.
Let's consider common distribution schemes as an example. Almost every product we buy as consumers comes to us through a multitiered distribution mechanism. Our local grocer stocks a store based on a detailed understanding of local demographics and buying behavior. The products that fill the shelves of the local grocery come shrink-wrapped on pallets and packed in boxes from a centrally-located warehouse. The warehouse, in turn, is fed by many consumer packaged-goods manufacturers such as candy makers, cereal companies, and bakeries.
Manufacturers, wholesalers, distributors, and retailers have refined this distribution model for more than 150 years; yet, after two generations of decision-support architectures, information technologists are just now discovering that information is a product, built by knowledge workers from data that is warehoused on the basis of economy and ease of distribution, and retailed based on local need. By understanding this simple idea, you can effectively join data warehousing and data marting into a hybrid enterprise DSS model that offers most of the benefits and avoids most of the limitations of both approaches.
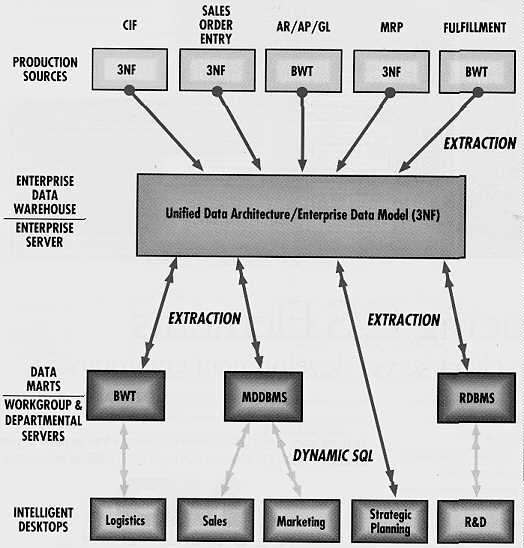
Figure 4 -- Demarest's Hybrid Warehouse/Marting Model
The IS organization must treat the individual business team -- the owner of a product, process, market, or customer -- as the primary customer of the enterprise's information. Only then can IS deliver business information (and the tools to analyze that information) in a supply chain that works for every business team. The IS organization must recognize that each business team requires an appropriately detailed vertical view of the historical data for the product, process, market, or customer for which it is responsible. Each business team requires an aggregated, horizontal view of the whole enterprise, including vertical views of the business teams that constitute its internal suppliers, collaborators, and customers. The team also requires full and seamless integration of the vertical and horizontal views of the enterprise data with the business team's group productivity software and GUI workstations.
In the delivery of decision-support data to business teams, I've identified four distinct processes:
1. Extract all data relevant to the business decision-making processes of groups of knowledge workers from the specific production (OLTP) systems responsible for capturing that information. The extraction process includes extracting copies of the relevant data from the OLTP sources, scrubbing that data to remove anomalies, inconsistencies, and unnecessary information, and enriching the data by translating cryptic numeric codes and acronyms into easy-to-understand textual (and in some cases graphical) information.
2. Store the resulting data sets in one location: the data warehouse. Because the sources of decision-support data are diverse and sometimes unconnected, the data sets created by the extraction process are stored in an EDM. This is a data schema that represents a simplified, but accurate, picture of the major business processes such as the manufacturing/product processes and marketing/sales processes. This model represents only a best-case approximation of the actual enterprise.
3. Create a unique cut or series of cuts of the data warehouse for each knowledge worker community. These are the "data marts," each of which fulfills a different user constituency's business need. For example, customer-support representatives, product marketing managers, and senior managers represent three distinct knowledge markets into which IS must sell different knowledge products. Customer-support reps may think of "customers" as individual names within corporate entities, and measure time in days. Marketing managers may think of customers as corporate entities within distinct market segments, and measure time in months, quarters, and years. Senior managers may think of customers strictly as corporate entities, and measure time in quarters and years. Different knowledge worker communities must view key dimensions of the enterprise at different levels of detail. The detail data in the warehouse must be rolled up to a higher level, or aggregated, to match each community's understanding of the business.
4. Supply the decision-support tools appropriate to the knowledge workers' style of computing. Returning to our previous example, customer-support representatives' model of data might be electronic and paper forms. Their computer applications may blend decision support and OLTP during a single customer call. In contrast, product managers think of data in terms of electronic spreadsheets, and senior managers think of data in terms of reports, briefing books, or presentations. The skill and comfort levels among knowledge workers also vary. For instance, a customer-service representative may be quite comfortable operating a personal computer, while senior managers may exhibit discomfort or lack interest in using them. This means that you must tailor the decision-support toolset to each information segment that IS serves.
These processes comprise an information manufacturing process and operational model in which corporate IS creates and manages a corporate data warehouse for the divisional and departmental IS organizations. These outlying organizations then tailor the information storage and access for their markets by building data marts and creating both host-based and client/server decision-support toolsets, according to local architectural practice.
Combining data warehousing and data marting, and factoring in the reengineering of production data as well as the complexities of client/server data access and analysis, results in the enterprise DSS model illustrated below.

Figure 5 -- Warehouse/Marting Model: Software Architecture
The point of data warehousing is to bring together from diverse transaction-processing systems the data required by business decision makers, and store it in a single unified model of the enterprise. As such, there should be only one data warehouse for the enterprise. Because the data warehouse stores the information for the entire enterprise, it must reside at the heart of the enterprise's network environment, as close as possible to major OLTP systems, and within reach of any system that captures data of interest to end-user communities.
The data architects managing the warehouse must have the organizational and technical prowess to negotiate with each organization that contributes to the data warehouse. The data architects drive the company's fundamental business models into the data architecture, not the other way around. They also manage the data store that holds the historical data for all these business processes, and they have a unique and broad-based view -- technically and procedurally -- of the enterprise.
The data warehouse contains the enterprise's most important asset: its historic data. The EDM framework employed by the data warehouse reschematizes information from each data source into a model of all the enterprise's major processes -- manufacturing, marketing, and sales. It joins each process to other processes, eliminates duplicate information, and ensures a seamless integration of the various data streams into one legible whole.
The data loaded into the EDM is stored at the lowest level of detail, such as individual customer names, product UPC and SKU codes, individual sales orders, and invoice line items. One or more of the user communities served by the data marts will need this level of detail. Of course, no user community will need all this detailed information.
The EDM is an evolutionary model. It is not possible to construct a complete EDM and populate it immediately; rather, the EDM evolves as the business evolves, and it becomes increasingly complete as businesses contribute production data to the warehouse.
The warehouse must know how to talk to each of the production systems that feed it information, in the native language of that production system, such as SNA, DECnet, or open systems protocols such as TCP/IP. The warehouse must also know how to ask for the data it needs, using SQL or other access languages for nonrelational formats such as VSAM and QSAM. This task is assigned to the warehouse (not to each data mart) to minimize data traffic and the impact on the production systems. The warehouse must know how to respond to requests for extracts from the data marts. This offers IS the opportunity to streamline its communications network by permitting only one kind of network connection (such as TCP/IP) to the warehouse.
In designing the system, IS must also choose whether to store the data extraction instructions in the "pump" used by each data mart or in the warehouse itself. Storing the instructions in each data mart enables it to command the attention of the data warehouse, where the mart acts as the master and the warehouse as the slave. This lets divisional IS customize extracts for its data mart customers more easily.
Conversely, storing the instructions in the warehouse lets central IS control the information given to the data marts. In this case, the warehouse tells the mart when it will receive data and what that data will look like. The mart is the warehouse's slave. Where the control resides is a policy issue that an enterprise must resolve based on its approach to data management and the requirements of its end-user communities.
The reasons to limit direct access to the data warehouse are related to the costs of communications and processing power (on the warehouse platform), data security and reliability, and data availability during batch updates and extractions. Instead of giving many knowledge user communities direct access, you should give access to a small community of users including the corporate IS data architects and a subset of knowledge workers who must access vast amounts of unaggregated data. These knowledge workers may be analysts who use statistical tools to analyze or predict market trends and financial performance, managers who use complex, intelligence-augmented modeling tools to predict business unit performance based on historical data, or corporate reporting personnel.
Data Mart Details
Data marts are the "corner stores" of the enterprise, and each unique knowledge worker community has its own mart maintained by the divisional or departmental IS group. Some divisions may need only a single data mart if all knowledge workers in the division have similar information requirements. In other cases, a departmental IS organization will discover several distinct knowledge worker communities within a single department of a division.Each data mart serves only its local community, and is modeled on the information needs of that community. For example, managers of consumer products will require different information than managers of industrial products (raw material). Consumer products have a complex competitive dimension for which syndicated market information (from companies such as Information Resources Inc. and Nielsen Marketing Research) exists, while industrial products have a simpler competitive dimension. Consumer products are sold over the counter with no advance notice of purchasing, while industrial products are sold in large lots over a longer period on the basis of existing relationships and contracts. Also, consumer products are sold through channels not controlled by the manufacturer, while industrial products are supplied directly by their manufacturers. These two communities, both composed of product managers, have different information requirements.
One of the most difficult practical problems in large organizations is drawing treaty lines between the corporate regime's IT function and the IT functions of divisions and strategic business units. Organizations can end the information wars between these regimes by placing responsibility for data marting squarely into the IT function closest to the end-user constituency. In the enterprise's information economy, corporate IS has the responsibility to "manufacture" a basic information product. Driven by their unique business goals, divisional and departmental IS organizations must enhance and repackage the basic information products manufactured by corporate IS.
Rather than combining the data management and information access roles under corporate IS, data marting gives the information delivery role to divisional or avoid a least-common-denominator approach to providing information to vastly different user communities. With data marts, divisional or departmental IS organizations take responsibility for design and implementation of data marts. They can assess their customers' needs effectively, and select the appropriate technologies based on their costs and potential benefits. For example, some divisions will have homogeneous communities of terminal users; others will have mixed communities of terminal users, intelligent desktop users, and mobile workers who need both remote and local access to their data marts.
With the knowledge of their users, a divisional or departmental IS organization can build data models in their data marts that reflect the local business model in legible schema. In contrast, the data warehouse's UDA must enforce a global model of the enterprise by embodying key objects such as sales, markets, and customers at the lowest possible level of detail.
The data mart's primary mission is to extract the base data required by a knowledge worker community from the warehouse, transform the data, and load it into the local business model in a manner that facilitates high-performance response to end-user requests. The data warehouse is built for bulk extracts and copying data to data marts. Data marts are built for fast response to specific questions from one or many simultaneous end users. This implies that the data mart is organized and indexed differently from the warehouse, and it anticipates commonly asked questions by hard-coding the answers instead of building the answers dynamically. Also, the data mart contains the systems management and monitoring tools needed to answer the management question, "What questions are end users asking?"
Finally, too many organizations make the mistake of assuming that the key to successful enterprise DSSs is to standardize on a single toolset that locks its customers out of the rapidly developing client tool and middleware DSS markets. Data marting lets each constituency choose a toolset that is appropriate to its business team, and provides clear boundaries and interfaces with which these toolsets must conform. The mart is better able than the warehouse to handle the complexities of end-user access.
The Next Generation
The first generation of DSS models, based on mainframe technology supporting both DSSs and production systems, proved unworkable. The production systems' data models were too complex for end users to understand, and the DSS and OLTP applications had to contend for the same precious computing resources.
The second generation of DSS models also proved unworkable. Corporate IS consolidated enterprise data on single, large systems, but did not consider data legibility or end-user access. Other organizations pursued isolated, unarchitected departmental marting strategies, creating network and extraction chaos and damaging the data integrity of the enterprise. The warehouse is still a data vault, and in many cases employs the same proprietary technology that continues to contribute to the lack of data-based decision making. Data marts, on the other hand, provide business teams with useful information, but the knowledge workers see only a small segment of the company's actual business. Also, the administrative burden on corporate IS and the burden of extracting data from production systems is too great for organizations to sustain.
The third generation of DSSs emphasizes the cooperative role of the data warehouse (the corporate data store) and data marts (the corner information stores of the online enterprise), and the time is right to build this hybrid enterprise DSS model. Both in-house and consulting DSS specialists still have a lot of work to do in architecture, design, and integration, but at least they now have the tools to do it.
Last updated on 06-22-97 by Marc Demarest (marc@noumenal.com)
The text and illustrations in this article are copyright (c) 1994 by DBMS Magazine and Marc Demarest.
The authoritative source of this document is http://www.noumenal.com/marc/marts.html